|
|
|
|
|

|

|
Dataset: Development of a method for discrimination of proteins requires both positive and negative examples.Here,
we have used the histone proteins as positive examples and non-histone proteins as negative examples. The positive dataset consisted of 652 histone p
roteins belonging to various classes of histones as shown below.

This dataset was obtained from the histone database at NHGRI (Sullivan et al., 2002), it is non redundant, and only contain complete histone sequences
. The negative dataset consisted of 1014 nuclear proteins other than histones. This negative dataset only contain distinct sequences, and has been d
erived form a collection of sequences used before in developing methods for subcellular localization of proteins including NNPSL,ESLpred.
Prediction Strategy:
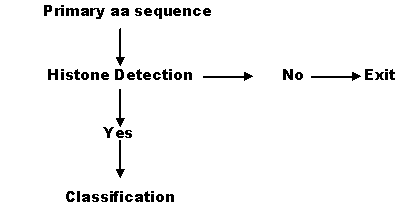
Computational approach:In this study we have choosen the SVM for both discrimination and
classification of histones.The Support Vector machine is universal approximators that can be used to learn a variety of representations from training
samples and as such, are applicable to classification tasks and regression tasks (Vapnik,1998). The unique ability to develop models with superior gen
eralization capabilities when the number of input features is large as compared to number of training samples is making this emerging technology the t
ool of choice among the various supervised learning algorithms, including ANNs.Here we have implemented the SVM_light package of SVM to classify the d
ata of histones and non-hstones.The SVM _light is freely available at http://svmlight.joachims.org.
Discrimination of Histones and non-histones:
For discrimination of histones and non-histones, we have developed a binary module using the SVM. The module was trained with histones as positive exa
mples and non-histones as negative examples.The SVMs require a fixed number of inputs for training, thus necessitating a strategy for encapsulating th
e global information about proteins of variable length in a fixed length format. The fixed length format was obtained from protein sequences of variab
le length using amino acid and dipeptide composition.
- Amino Acid Composition:- Protein information can be encapsulated in a vector of 20 dimensions, using amino
acid composition of the protein. The amino acid composition is the fraction of each amino acid type within a protein.
- Dipeptide Composition:-
The dipeptide composition was used to transform the variable length of proteins to fix
ed length feature vectors. We adopted the same dipeptide composition-based approach in developing an SVM-based method for predicting subcellular local
ization of eukaryotic proteins. The dipeptide composition gave a fixed pattern length of 400. Dipeptide composition encapsulates information about ami
no acids and their loacl order.
Classification of histones:
The classification of an unknown histone into a particular family is a multiclass problem. We constructed K binary SVM classifiers for K subfamily cla
ssifications. The i-th SVM was trained using all sequences of the i-th subfamily with positive labels and the sequeence from the other subfamilies wit
h negative labels. For example the module for histone 1 (H1) was trained with all the examples of H1 family as positive label and examples of rest of
families (H2,H3,H4,H5) as negative label. SVMs trained in this way are referred to as one-versus-rest SVMs. In this way for 5 families of histones 6
SVM modules were generated (2 for H2 family).
Evaluation of performance:
The performance all classifiers was evaluated through 5-fold cross validation. In 5-fold cross validation, the data set was partitioned randomly to fi
ve equally sized sets. The training and testing was done 5 times each time using one distinct set for testing and 4 sets for training.
The performance of classifiers was evaluated by measuring accuracy and the MCC for each family of histones, as described by Hu
a and Sun (2001).
Reliability Index (RI):- The determination of prediction reliability is important when using machine learni
ng techniques to assign subfamilies of nuclear receptors. The reliability index (RI) was assigned on the basis of difference () between highest and se
cond highest value of SVMs in multi-class classification. RI provides an insight into the accuracy/reliability of prediction as shown below.
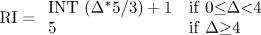
|
|
 |
|

|
|
| Citations:
|
- Bhasin M, Reinherz EL, Reche PA.

|
Comments & Help: Pedro Reche

|
|
 |
Hits since June/2004

|
Last updated:
|
|
|
|
|
|
|
|
|
|
|
|
|